消息队列服务Kafka揭秘 痛点、优势与适用场景
随着企业数据规模和系统复杂度的不断攀升,信息集成与异步通信成为系统架构中的核心挑战。Apache Kafka作为一款分布式流处理平台和消息队列服务,凭借其高吞吐、可扩展和持久化的特性,在众多领域脱颖而出。本文将深入解析Kafka的核心原理,剖析其使用中的痛点与独特优势,并探讨其典型的适用场景。
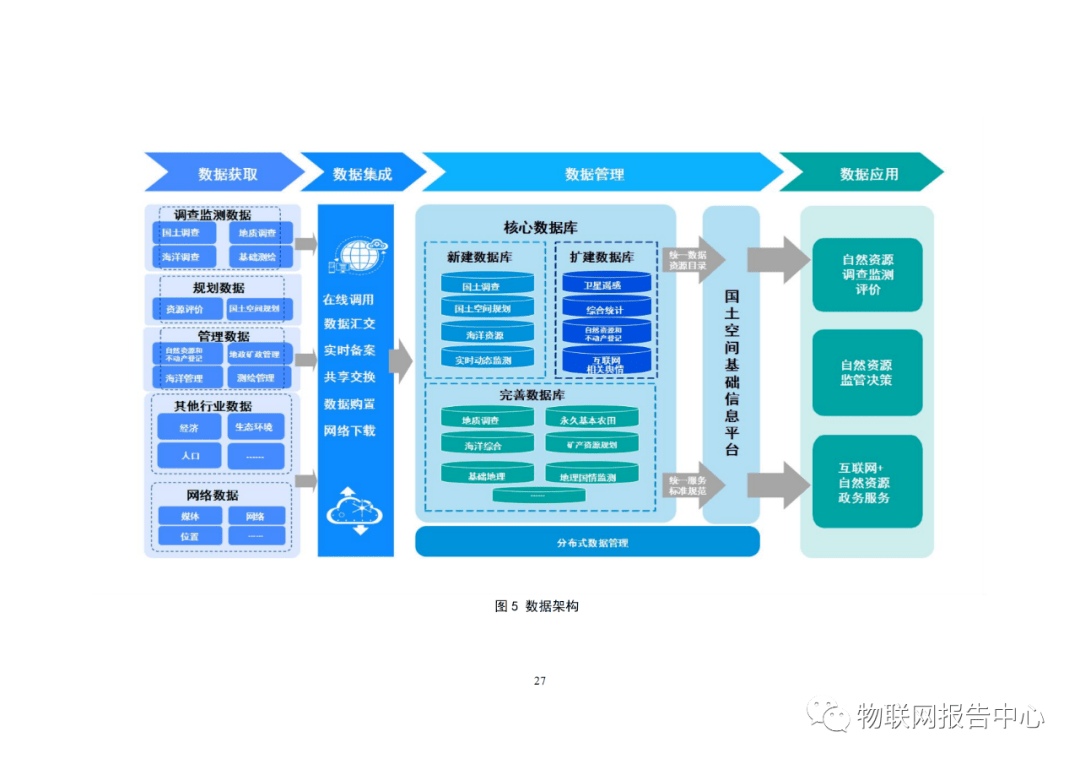
Kafka的核心架构与工作原理
Kafka本质上是一个基于发布/订阅模式的分布式消息系统。其核心架构主要由以下几个组件构成:
- Producer(生产者):负责将消息发布(推送)到指定的Topic(主题)。
- Consumer(消费者):订阅一个或多个Topic,并从中拉取(pull)消息进行处理。
- Broker(代理服务器):Kafka集群中的单个节点,负责消息的存储和转发。
- Topic(主题):消息的逻辑分类,生产者将消息发送到特定Topic,消费者订阅感兴趣的Topic。
- Partition(分区):每个Topic可以被分为多个分区,分布在不同的Broker上。分区是实现水平扩展和并行处理的基础。
- ZooKeeper:在早期版本中,Kafka依赖ZooKeeper进行元数据管理和集群协调(如Broker注册、Leader选举)。新版本正逐步移除对ZooKeeper的依赖(KIP-500)。
其工作流程是:Producer将消息发送到指定Topic的某个分区;消息被顺序、持久化地存储在分区日志中;Consumer通过维护自身的偏移量(offset)来跟踪消费进度,从而可以灵活地重放历史数据。
使用Kafka可能遇到的痛点
尽管Kafka功能强大,但在实际应用中,开发与运维团队也面临一些挑战:
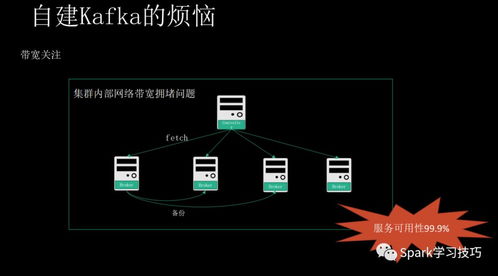
- 运维复杂度高:Kafka集群的部署、监控、调优和扩容需要专业的知识和经验。涉及Broker、ZooKeeper、网络、磁盘I/O等多方面的配置与管理。
- 概念与配置繁多:对于初学者,分区、副本、ISR、ACK机制、日志保留策略等概念需要时间理解。不恰当的配置(如
acks、retries、compression.type)可能直接影响系统的可靠性与性能。 - 客户端生态与版本兼容性:Kafka拥有多语言客户端,但其成熟度不一。服务端与客户端版本的兼容性问题有时会带来意想不到的麻烦。
- “Exactly-Once”语义的实现复杂度:虽然Kafka提供了事务API以实现精确一次处理语义,但其实现相对复杂,对应用设计和性能有一定影响。
- 资源消耗:为了达到高性能,Kafka会充分利用页缓存(Page Cache),对内存需求较高。其持久化机制意味着需要提供高性能的磁盘存储。
- 不适合小规模场景:对于非常简单的、低吞吐量的应用,引入Kafka可能会带来不必要的架构复杂度和运维负担。
Kafka的显著优势
面对上述痛点,Kafka之所以仍被广泛采用,归功于其不可替代的优势:
- 高吞吐量与低延迟:通过顺序I/O、零拷贝(Zero-Copy)和批处理等技术,Kafka能够轻松处理每秒数百万条消息,同时保持毫秒级的延迟。
- 高可扩展性:通过增加Broker即可水平扩展集群,通过增加分区即可提升单个Topic的并行处理能力。扩容过程通常对服务影响较小。
- 持久化与高可靠性:消息被持久化到磁盘,并支持多副本(Replication)机制。即使部分节点失效,数据也不会丢失,服务仍可继续。
- 高并发与容错性:多个Consumer可以组成消费者组(Consumer Group),共同消费一个Topic,实现负载均衡和并行处理。消费者加入或离开组时,集群会自动进行重平衡(Rebalance)。
- 强大的流处理能力:Kafka不仅是一个消息队列,其核心的Kafka Streams库以及与之紧密集成的Kafka Connect,使其能够构建强大的实时流处理管道,进行数据的转换、聚合和填充。
- 生态繁荣:Kafka与大数据生态(如Hadoop、Spark、Flink)结合紧密,是现代数据湖、数据仓库中实时数据摄入的关键组件。
典型适用场景
基于其特性,Kafka在以下场景中表现尤为出色:
- 实时日志流收集与聚合:经典的“日志中心”场景。各类应用、服务将日志统一发布到Kafka,再由下游的日志检索系统(如ELK)、监控系统或数据仓库进行消费和分析。
- 网站活动追踪:记录用户的页面浏览、点击、搜索等行为事件,用于实时分析、个性化推荐或用户行为建模。
- 消息驱动型微服务架构:作为微服务之间的异步通信总线,实现服务解耦、削峰填谷和最终一致性。例如,订单服务产生订单事件,库存服务、物流服务异步订阅并处理。
- 流式数据处理管道:作为实时数据管道,连接数据源与流处理引擎(如Flink、Spark Streaming)。例如,物联网设备数据上报、金融交易实时风控。
- 事件溯源(Event Sourcing):将系统的状态变化记录为一系列不可变的事件,并存储于Kafka。系统状态可以通过重放事件来重建,为审计、调试和构建衍生数据视图提供了极大便利。
- 操作指标(Metrics)与监控数据流:收集分布式系统中各节点的性能指标,进行实时监控和告警。
###
Apache Kafka是一个为处理实时数据流而生的强大平台。它并非一个简单的“消息队列”,而是一个分布式的、高可靠的、支持流处理的提交日志系统。企业在引入Kafka时,需充分权衡其带来的高性能、解耦能力与随之增长的架构和运维复杂度。对于需要处理海量实时数据、构建松耦合、可扩展的现代分布式系统的场景,Kafka无疑是一个经过大规模实践验证的卓越选择。理解其痛点、善用其优势,方能使其在企业的技术架构中发挥最大价值。
如若转载,请注明出处:http://www.njjhm.com/product/9.html
更新时间:2026-06-19 15:03:02